
How do HDDs affect database operations?
How do Hard Disk Drives work?
An HDD is a non volatile storage device which stores the data in a form of a magnetic field. The HDD is made out of multiple magnetic platters (from one to five) and pair of arms below and above of each platter.
Each platter contains multiple tracks which is a circular path on the platter. Tracks contains smaller chunks called sectors. Data is read and written sector by sector using the arms. Sectors usually have sizes in range from 512 B to 16 KB. And a single track can have many sectors depending how far away is track from the center of the platter.
Modern HDD mostly
have 16 KB sectors. It is important mentioning that HDD devices guarantee that
the writes of sectors will happen atomically. Here is my humble hand drawn
representation of this:
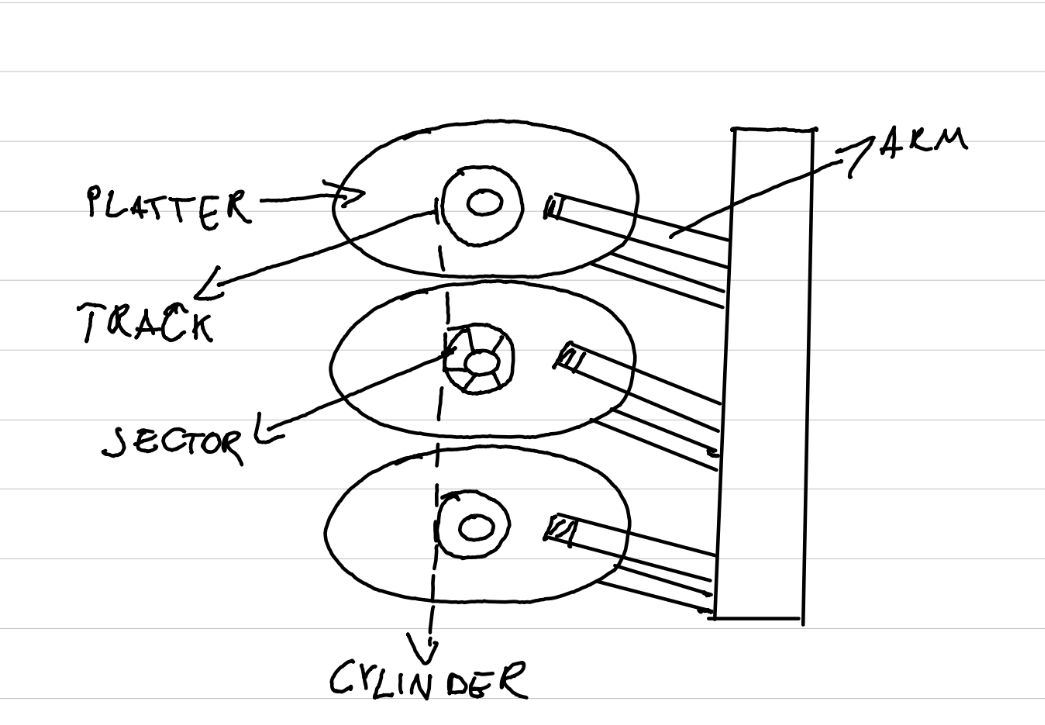
The mechanism of writing and reading data is based on magnetic field of the platters. When disk arm generates current it changes the magnetic field of the platter, which writes the data down. Detecting the magnetic field in arm generates current in arm and therefore reads the data. Newer HDDs have separate heads for reading and writing the data.
An interesting question to ask is why not add multiple arms to increase HDD speed and add internal parallelism like SSDs have? As said in this answer the issue is that would introduce additional complexity of calculating and moving the arms and would also create more heat within the HDDs, and besides that they would be much more expensive for consumer grade products. But looking at the existing HDDs there are some implementing multiple arms e.g. Seagate MACH.2
Latency
When the HDD needs to read the data few things have to happen first:
- The OS provides the exact block/sector that needs to be read from the disk.
- The HDD calculates on which track and platter the sector is located on.
- If the arm is not at the position of the correct track, arm has to be repositioned, this is called seek time and it ranges from 2 ms to 20 ms depending on how far away they are.
- After that the platter keeps rotating until it finds the correct sector this is called rotational latency time. This time can range between 4 ms and 11 ms per rotation. Full access time is the sum of seek time and rotational latency time. In summary:
It is exactly this process that makes the sequential reads very fast, but random ones slow. Since for the sequential the seek time and the rotational latency time are minimized.
We can express the total latency of a disk read to be:
TotalLatency = SeekTime + RotationalLatencyTime
which for our estimation can be in range of 5 - 31 ms.
Bandwidth
But bandwidth of HDD can vary greatly from one manufacturer to other, but accepted bandwidth rate for reading/writing is 30-150 MB/s. SATA cables are not a bottleneck, since SATA 3 transfer speed is around 6 Gbit/s which is 750 MB/s, more then HDD bandwidth.
Sequential vs Random access
Let us try to test out he difference between random and sequential access to compare the speed and see the effect on the write/read operations. I will be using fio to measure different workloads on a HDD. I am using: Seagate ST4000VN006-3CW104 which according to the specification has:
- rotational speed 5400 RPM, which means it needs 11.11 ms to do a full rotation,
- maximum read speed of 252 MB/s and maximum buffered read speed of 492 MB/s,
- average seek time 12 ms.
I am interested if the tests with fio will match the results in specifications, so lets see. Checking my HDD block size:
$ cat /sys/block/sdc/queue/physical_block_size
4096
we can see that the block size of my HDD is 4KB.
Sequential workload
Now lets set up a fio job using this configuration for sequential read:
[global]
name=fio-seq-reads
filename=fio-seq-reads
rw=read
bs=4K
direct=1
numjobs=1
time_based
runtime=900
[file1]
size=10G
ioengine=libaio
iodepth=16
and the results are:
Starting 1 process
file1: Laying out IO file(s) (1 file(s) / 10240MB)
Jobs: 1 (f=1): [R(1)] [100.0% done] [508.8MB/0KB/0KB /s] [130K/0/0 iops] [eta 00m:00s]
file1: (groupid=0, jobs=1): err= 0: pid=20: Sun Apr 6 18:42:45 2025
read : io=441519MB, bw=502350KB/s, iops=125587, runt=900001msec
slat (usec): min=5, max=356, avg= 7.03, stdev= 0.98
clat (usec): min=9, max=45229, avg=120.08, stdev=83.00
lat (usec): min=17, max=45236, avg=127.16, stdev=82.99
clat percentiles (usec):
| 1.00th=[ 108], 5.00th=[ 111], 10.00th=[ 113], 20.00th=[ 115],
| 30.00th=[ 116], 40.00th=[ 117], 50.00th=[ 118], 60.00th=[ 119],
| 70.00th=[ 120], 80.00th=[ 121], 90.00th=[ 124], 95.00th=[ 126],
| 99.00th=[ 133], 99.50th=[ 173], 99.90th=[ 494], 99.95th=[ 516],
| 99.99th=[ 1464]
bw (KB /s): min=139816, max=549520, per=99.99%, avg=502303.81, stdev=51861.89
lat (usec) : 10=0.01%, 20=0.01%, 50=0.01%, 100=0.01%, 250=99.53%
lat (usec) : 500=0.37%, 750=0.06%, 1000=0.01%
lat (msec) : 2=0.03%, 4=0.01%, 10=0.01%, 20=0.01%, 50=0.01%
cpu : usr=8.37%, sys=89.98%, ctx=45150, majf=0, minf=25
So in tests we can see that the overall read bandwidth is around 500 MB/s and average latency is 127.16 µs for a sequential workload. Out of three sets of running fio test I took the median one.
Random workload
The only change in the fio run configuration made is in the rw fields, and changed
it to randread.
The results gotten from these runs are
Starting 1 process
file1: Laying out IO file(s) (1 file(s) / 10240MB)
Jobs: 1 (f=1): [r(1)] [100.0% done] [1162KB/0KB/0KB /s] [290/0/0 iops] [eta 00m:00s]
file1: (groupid=0, jobs=1): err= 0: pid=26: Sun Apr 27 17:24:45 2025
read : io=998928KB, bw=1109.9KB/s, iops=277, runt=900076msec
slat (usec): min=4, max=3098, avg=19.69, stdev=14.00
clat (usec): min=200, max=915661, avg=57641.95, stdev=63896.23
lat (usec): min=208, max=915693, avg=57661.96, stdev=63896.14
clat percentiles (msec):
| 1.00th=[ 6], 5.00th=[ 8], 10.00th=[ 10], 20.00th=[ 14],
| 30.00th=[ 20], 40.00th=[ 27], 50.00th=[ 36], 60.00th=[ 48],
| 70.00th=[ 64], 80.00th=[ 89], 90.00th=[ 135], 95.00th=[ 184],
| 99.00th=[ 310], 99.50th=[ 367], 99.90th=[ 502], 99.95th=[ 562],
| 99.99th=[ 676]
bw (KB /s): min= 656, max= 1301, per=100.00%, avg=1110.51, stdev=74.46
lat (usec) : 250=0.01%, 500=0.01%, 750=0.01%, 1000=0.01%
lat (msec) : 2=0.01%, 4=0.15%, 10=11.73%, 20=19.24%, 50=30.84%
lat (msec) : 100=21.17%, 250=14.75%, 500=1.98%, 750=0.10%, 1000=0.01%
cpu : usr=0.31%, sys=0.83%, ctx=251990, majf=0, minf=26
Here we see that the overall read bandwidth is around 1109.9 KB/s or 1.1009 MB/s and average latency is 57661.96 µs for a random workload. Which is a huge difference from the sequential load from before. Bandwidth is around 500 times lower and the latency is around 450 times bigger compared to sequential workload.
For HDD it is very important how many sequential reads we have since it can make all the difference. Therefore the data structures that are designed for HDD usually implement some sort of space locality when inserting data, so that the most relevant data is physically closer on disk.
Analysis
But lets try to see how does theory matches the measured data here:
| Measured | Sequential | Random |
|---|---|---|
| Latency [µs] | 127.16 | 57661.96 |
| Bandwidth [MB/s] | 500 | 1.109 |
| IOPS | 125587 | 277 |
In theory we should not have experienced a bigger latency then 31 ms, and here we measure almost 57 ms, why is that? And plus that we see much lower IOPS executed in random workload.
The latency we measure is from the point that user issues IO operation,
the request is not immediately executed by HDD but it is queued since we are probably waiting on
the previous IO operation to be executed and so on. We could have limited this in fio test by
setting iodepth to 1.
References
- https://en.wikipedia.org/wiki/Disk_read-and-write_head
- https://superuser.com/questions/107723/hard-drive-sectors-vs-tracks
- Database System Concepts 7th Edition, Abraham Silberschatz, Henry F. Korth, S. Sudarshan
- https://github.com/axboe/fio
- https://www.seagate.com/www-content/datasheets/pdfs/ironwolf-18tb-DS1904-20-2111US-en_US.pdf
- https://smarthdd.com/database/ST4000VN006-3CW104/SC60/
- https://www.seagate.com/www-content/product-content/ironwolf/en-us/docs/100807039m.pdf